Generative AI (doesn’t that term feel like such an antiquated relic these days?) and LLM-powered agents feel as big a technological leap as the internet was for humanity, and for good reasons. Finally, the dream of artificial intelligence is materializing. You no longer need to train your own model to solve your specific problem. For the past four years, we have had general-purpose AI which is multi-modal, capable of reasoning and using tools.
“As big as the internet was”, of course, comes with the same level of risks, and the biggest of them all is: being misunderstood as a silver bullet for humanity’s problems. Beneath the torrential flood of “magic-like” hype declarations lies a quieter undercurrent of failures. While the demos are polished, the reality checks are starting to surface. Many in the industry aren’t ready to look at them yet, since there is still hype left to milk.
Table of Contents
- The Three Tiers of Agency
- You Are an AI Pessimist, Whether You Are One or Not
- The False Promise
- Architecting Autonomy
- Final Thoughts
First let’s agree on what we’re talking about here: when a tech CEO is talking about agents today, they’re most likely talking about a fully autonomous agent that needs nothing but an instruction and some integrations to get you a “done job”. The job, critically, is often a very ambitiously and vaguely defined task like: “develop and execute a communication strategy”, the underlying dream scenario being “spending on tokens instead of on people”.
When a software engineer is talking about a coding agent, they’re most likely referring to Claude Code, OpenAI Codex or Google Gemini CLI - and in some cases an “AI software engineer” (if such a thing is even plausible) like Devin. That is very different from the above.
Regular people? They think ChatGPT is an agent.

The Three Tiers of Agency
To discuss this effectively, we must move past marketing fluff. True agency is a spectrum, and I define it across three levels:
- Level 1: Tool Use. The ability to call external APIs or execute local functions. Essentially, a chatbot with a backpack.
- Level 2: Chain-of-Thought. Sequential planning where the AI breaks a task into steps and executes them one by one.
- Level 3: Autonomous Agency. The “Uncanny Valley” of frameworks. This requires asynchronous execution, self-correction, and state persistence (memory).
Level 3 is where the current hype lives, but it’s also where most frameworks fail. It’s the difference between an assistant that helps you write a function and an agent that “lives and breathes” inside your infrastructure, figuring things out and doing them itself.
So do “interactive” or “semi-automated” agents qualify for what most would call “agent” (as opposed to a classic chatbot or a coding assistant)? I don’t think so, I have seen the definition shift with time and right now most people I talk to define it as this idea of an enabled AI that “is living and breathing” and “figures it out and does it itself” - implying the idea of autonomy and memory as the end goal.
That will be my definition for “agent” going forward in this post.
Why is it then that whenever we get a demo of an agentic framework someone inevitably shows us an LLM “summarizing their agenda for the day” (I must have seen this one a dozen times from different providers each valued at hundreds of millions - but it’s not a bubble, relax everyone)? Isn’t it a bit telling that the pitch comes down to “We’ve replaced 15 seconds of cognitive effort with 45 seconds of LLM latency and a $0.12 API bill”? Why does this feel so much like the Mechanical Turk?

You Are an AI Pessimist, Whether You Are One or Not
The current Agentic AI hype is so aggressive that anyone questioning any part of it is labeled an AI pessimist. It always strikes me as a paradox: the people who use this technology daily and reap the most benefits from it are often the ones who see the flaws more clearly, and will therefore put them front and center because by this point, those people are expecting it to be great and to provide what everyone else is stuck praising and dreaming about, and doubting that others are not maximizing its ROI.
If you, like me, daily drive Claude Code and can’t remember the last manual line of code you wrote except for “claude --resume”, you will be more concerned about its failure to systematically apply the rules you set in your repo’s .agents folder than about “how amazing it is”. It’s simple really, and this meme that everyone has seen by now summarizes it perfectly:

At first, it was unsettling to me seeing people misunderstand my recurrent critiques of this wave of AI tools as “AI skepticism” and “AI pessimism” and “yet another IT guy scared for his job”.

Until you really listen to what’s being said.
In reality, the displacement will likely be felt most outside the technical sector. Engineers have gained a level of leverage that was previously unimaginable. We can now build and scale at a fraction of the cost, making the capital-intensive startups of the past look inefficient, although that is a deeper conversation for another day.
Then when I thought about who is actually using this technology more and thus has a better insight into it from the two sides of this exchange, it restored my conviction that this is yet another symptom of the duty of toxic positivity tech “visionaries” impose on all of us.
If you’re not on the bandwagon, you’re falling behind and don’t see the potential and thus can’t capture the opportunity, or so it goes.

If you’re not chanting praise to the agentic brave new world with the crowd, you’re a bad engineer.
The truth is that those who still pitch this technology as a magical, cost-free panacea are the ones truly trailing the curve. By ignoring the complexities of implementation, they miss the actual structural shift occurring in the industry.
This train of thought is not original either, because this whole thing is happening for the 10th time at least, in tech history.
The False Promise
In a nutshell, 1) easy, and 2) ubiquitous automation is what’s being promised here. Sure it can summarize your calendar, but it can do much more if you want it to. Literally everything possible for you to do with a computer today. No really, that’s really what these things could can do.
Easy Automation
“As an agentic AI user, I would like my agent to do my chores, and make me a billion dollar SaaS, so that I can go for a walk and be happy”.
Implement this one,
<insert agent name here>.
This is the weight of the expectations here: It is in principle possible, but I have and everyone here has been provided access to the Zapiers and the Microsoft Power Automate and we found it such a chore to literally go and figure out the formalism and draw a workflow then input variables and link systems and services, who wants to do that? Can’t I just tell it what to do?
Well - you can now, it can understand what you want (or a version of it), and if you connect it enough, your agent can also do it for you. But how much “telling it what you want” are you ready to do?
the more you tell it what you want the more annoyed you are but the more informed it is
How reliably will it understand what you want?
the more you give it instructions the more confused it will get
So for now we’re stuck with glorified workflow management software with an “LLM” step as a nice new addition (instead of say coding a custom processing step), so basically classic BPM/workflow management and automation with “easy to make” NLP steps baked in.
People forget, but the last time we did this, you needed the subscription to the SaaS, the guy who sits down and slowly and painfully maps out your processes, then creates the flowcharts, then debugs the process execution, then maybe a couple of months later delivers a limited set of pre-determined workflows that work, but are not robust to changes or breaking integrations, thus tying you up in a maintenance contract and a long-term ✨yet another tool to maintain that’s also too painful to drop after all the time and effort we invested into it✨ ™️.
We don’t have “an agent that makes agents” yet. We will have it at some point, but we don’t have it yet.
The best we can do is to simulate it via “my agent instantiating sub-agents” which is (to anyone who knows) your AI assistant prompting itself concurrently to execute different parts of the task under different contexts/prompts/”personas”.

It is good, and useful - but it’s not yet an agent that makes agents in the deeply intuitive sense of the term.
Ubiquitous Automation
Connect your calendar, connect your Hubspot, your Salesforce, your SAP, your bank API, your robot vacuum cleaner app, your coding assistant, everything you can connect (and the list is rapidly growing) and you will have ubiquitous agency.
It makes all the sense in the world, and yet it doesn’t: you mean hand over all my keys to an agent run by some business somewhere and just trust them with my life?
No I’ll host my own.
Oh wait, what do you mean it can accidentally delete everything and has done it in multiple highly-publicized instances?
Ok I will restrict it from certain types of operations. But then it won’t be able to do ubiquitous automation for me - it won’t be fully automatic (i.e. agentic, as defined in the beginning), it will be a:

that is also not omnipotent. Nope, don’t take my money.
Who Is Making This Promise?
Interestingly, it is a mix of:
- people with a vested interest in making it sound too easy to drive adoption of their “coding agent” (I would call it a CLI coding assistant but that’s not as fun). This includes the highly publicized stories of 30 PRs a day that yield just top notch code if you follow these easy steps. It is a metric that sounds impressive to a CFO but terrifying to anyone who has to maintain the resulting technical debt. High-volume output is not a proxy for high-quality engineering, yet it is being sold as the new standard for the AI-enabled developer.
- managers, execs and visionaries who want to repeat it enough that it becomes a reality to which everyone has to catch up, also with a vested interest since it’s setting unrealistic expectations of their engineers who actually have to use the tools and build things with them.
- optimistic people who genuinely believe in the potential of these tools but lack the immersion necessary to understand what implementation of large-scale automation implies in terms of effort and investment.
This does not necessarily disqualify any of these actors, a healthy attitude would be to listen, analyze and understand where each is coming from, what their goals are and where the disconnect is happening - because only then can we begin to figure out how to handle these expectations and this fallacious promise.
The promise is valid in the long term - to some extent, until the LLM plateau theory is proven wrong. What is certainly wrong is the short term promises of easy and ubiquitous automation.
The Token Tax
You will notice I deliberately ignore the token tax argument here because I firmly believe that it is a temporary issue, and that with the massive investments in hardware and software being made into generative AI, tokens have been getting cheaper and will keep getting cheaper over time until they are a non-issue.
LLM inference prices have been steadily dropping across the board:
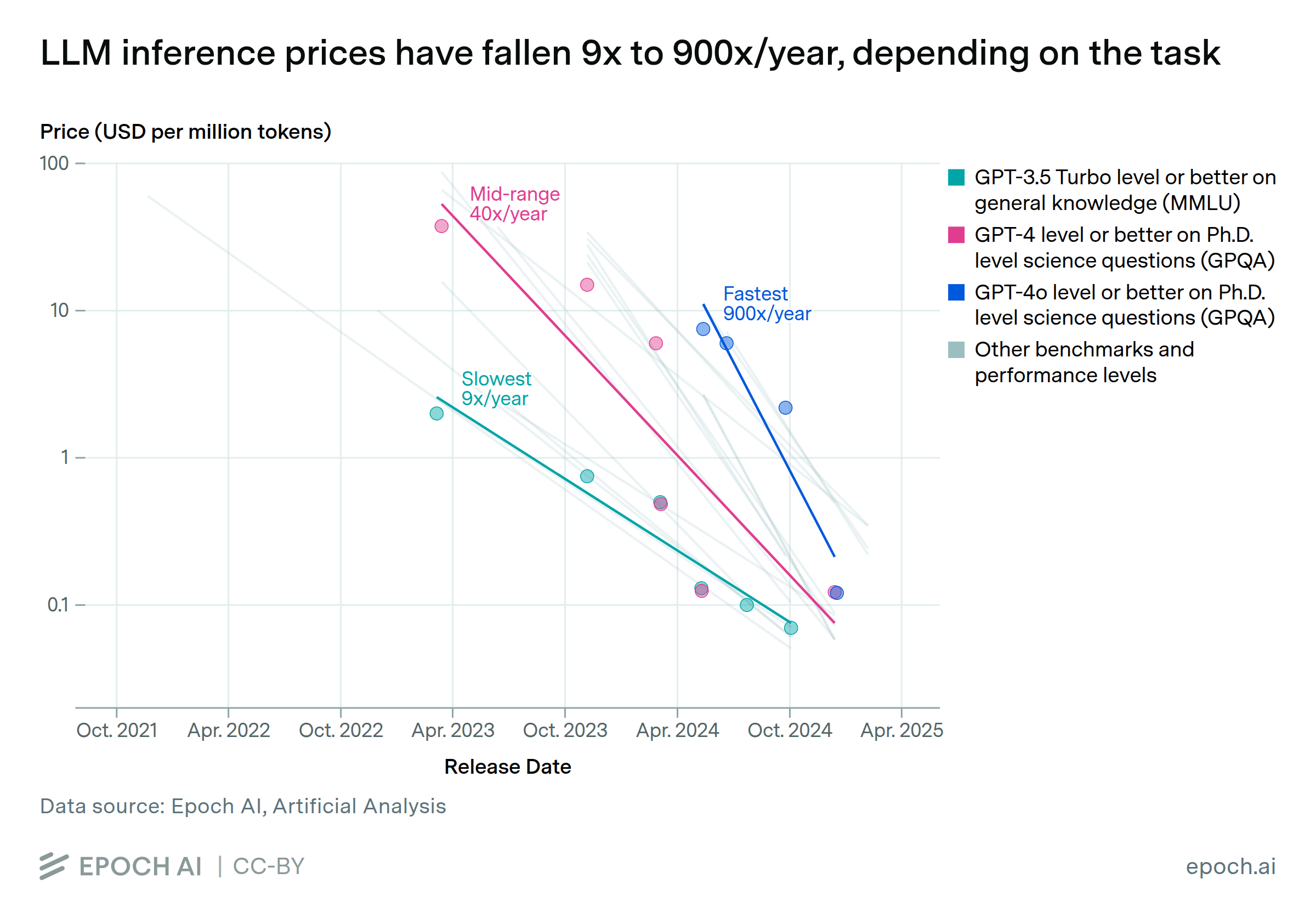
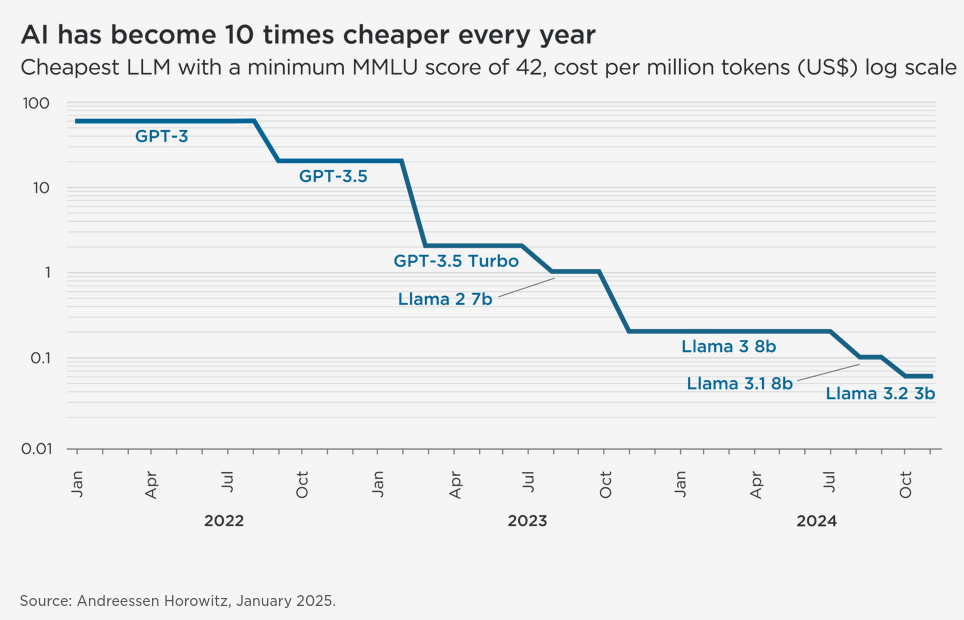
Price per token has also been steadily dropping (source):
Still, if you’re a budget-sensitive organization that can not sponsor tokens without limits (which is the case for most organizations aiming to benefit from agentic AI) you must carefully plan the investment and budgets and most of all ensure there are:
- Caps on token spend, so you don’t dangerously overspend
- No incentives to overspend and waste (like the ridiculous new “tokenmaxxing” trend and metrics set by management for engineers)
- Clear goals and a shared understanding of the expected ROI with the employees being provided these tools
Architecting Autonomy
By all measures, and beyond simply headlines and sales pitches, agents are here, and here to stay and become the new default.
Zooming out, for the first time in our history, we have invented a new type of program that has an infinitely flexible interface and can execute any request we make without pre-programming.
That in itself is the stuff of miracles.
Is it working? Are we getting easy ubiquitous automation? When it works, why? In which cases? When does it not work? The answers are all obvious for anyone who has seen the waves come and go - this is as transformative as the internet, but also suffers from the same paradigm shift issues as all the previous digitalization and automation waves: inflated expectations, botched planning and rushed execution.
Capturing this opportunity is possible, it’s happening, and there is a right way to do it: explore, while keeping a cool head about it and hedging against the tumultuous nature of the business environment surrounding it at the moment. Adopting a new tool every couple of weeks is possible, but it’s counterproductive. Spending time building automation workflows and pipelines for mundane tasks that take 3 seconds and don’t change the productivity picture for an employee is not a good investment.
If I had to summarize it, I would recommend three things:
-
Stick to the fundamentals
- Ask why, then what and only then ask how (although you may already have AI Agents as an answer going in). But trust me, this never fails: questioning your goal and what you are trying to build to achieve that goal will always lead you to the right “how”, the right tooling, process and eventually results.
- More formally: never compromise on architectural analysis. Before building a system, it is key to understand why you are doing so and what you need it to do. You will also find that documenting your architecture design and ADRs in a clean coding-agent-readable way helps, although it will always need some prompt engineering to take that into account.
- The smaller the problems, the more successful the implementation: by dropping the expectation of “easy” automation, you will start to be more explicit and specific in your asks from your AI agents, and that in turn will result in them delivering more successfully on your asks. You don’t have to do it by hand by the way: your agent is more than capable of making a solid step by step plan, you just have to review it and ensure it’s doing what you’re asking it to do.
-
Experiment and Adopt
- Start Small, Scale Slowly: Instead of chasing the latest “agentic” hype cycle, begin with low-stakes, sandboxed environments (like Dify or OpenClaw - I have tried both and would actually recommend Dify) to test specific workflows. Treat early adoption as a discovery phase, not a production rollout. This is not valid across the board, in some cases where repeated high-similarity actions are happening, adoption can move faster - as is the playbook of any type of digital automation of the past.
- Iterative Integration: Focus on integrating agents into existing workflows where they can augment human decision-making rather than replacing it entirely. The goal is to find the “sweet spot” where automation adds genuine value without introducing fragility.
- Tool Agnosticism: While the landscape moves fast, avoid the trap of constant tool-switching. Pick a stack that fits your current architectural needs and stick with it long enough to learn its nuances. True adoption comes from deep familiarity, not surface-level novelty.
-
Learn and Manage Risks and Limitations
- Acknowledge the “Black Box”: Understand that while agents are infinitely flexible, they are not omniscient. They suffer from hallucinations, context window limits, and reasoning gaps. Successful implementation requires building guardrails and human-in-the-loop verification steps, not blind trust.
- Acknowledge the inherent security risk that comes with handing over your data, API connections and prompt-derived intelligence to a third party automation platform. Self-preferencing by these platforms and replication of your workflows/data/knowledge to be sold to others without your knowledge is a real risk supported by many past incidents. Be aware of what your service providers are doing with your data, so that you don’t enable shadow AI risks. Many SaaS companies have enabled AI agents or AI training on their customer data with sometimes suspiciously quiet releases/updates, which can be very risky and result in data extraction by AI agents or LLM leaks in the future.
- Policy and Access Control: Do not grant your agents unfiltered access. What happens when an agent, tasked with “cleaning up Hubspot data,” decides that deleting 5000 “stale” leads is the most efficient path because it lacked a policy guardrail? Without OPA (Open Policy Agent) or similar proxies, you aren’t just deploying an assistant. You’re deploying a root user with a hallucination problem. Learning to define these constraints is as critical as learning to prompt the agent. Solution providers like Rubrik are starting to address this with commercial tooling, but the responsibility remains in the hands of the architect.
- Cost-Benefit Analysis: Recognize that not every task is worth automating. If a task takes 3 seconds and is stable, the overhead of building an agent pipeline may outweigh the time saved. Focus learning efforts on high-friction, high-complexity problems where human intuition is currently the bottleneck.
Final Thoughts
So why am I actually so worked up about all of this? Can’t I just let people be happy and name things however they want and dream a little?
It would be fine if it were just that, but what’s happening right now is malicious use of this language to overpromise and underdeliver, and in the process make massive profits from what is essentially deception.
Anyone working in IT/Software who has any respect for the profession, for their professional integrity, for their clients and their users will not engage in this, as tempting as it may be.
I believe that we all owe it to each other and to our communities to explain what’s happening from a realistic grounded and practical point of view, so we can maximize the ROI of this truly revolutionary technology while tuning out the noise and weeding out false claims and outright fraudulent pitches.